2018년 컴퓨터활용능력1급 2회차
60문제로 구성된 기출 시험
시험 문제
문제 1
해설
문제 2
해설
문제 3
해설
문제 4
해설
문제 5
해설
문제 6
해설
문제 7
해설
문제 8
해설
문제 9
해설
문제 10
해설
문제 11
해설
문제 12
해설
문제 13
해설
문제 14
해설
문제 15
해설
문제 16
해설
문제 17
해설
문제 18
해설
문제 19
해설
문제 20
해설
문제 21

해설
문제 22
해설
문제 23
해설
문제 24
해설
문제 25
해설
문제 26
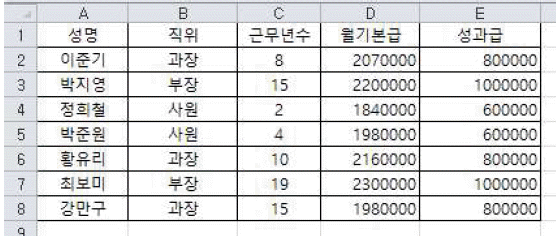
- ①행 머리글과 열 머리글이 만나는 워크시트 왼쪽 맨 위의 [모두 선택] 단추( )를 클릭한다.

- ②[A1] 셀을 클릭하고 < Shift >키를 누른 채 [E8] 셀을 클릭한다.
- ③[B4] 셀을 클릭하고 < Ctrl >+< A >키를 누른다.
- ④[A1] 셀을 클릭하고 < F8 >키를 누른 뒤에 <→>키를 눌러 E열까지 이동하고 <↓>키를 눌러 8행까지 선택한다.
해설
문제 27
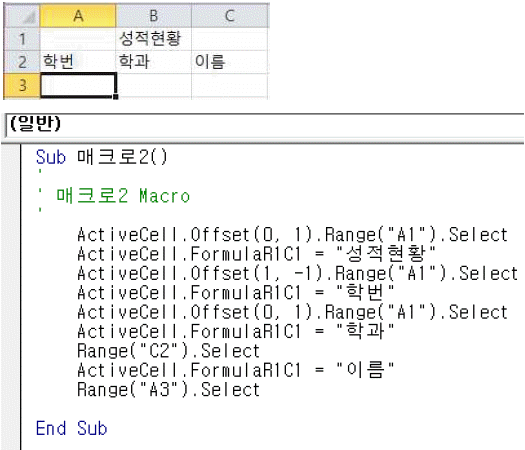
해설
문제 28
- ①엑셀의 현재 작업 상태를 표시하며, 선택 영역에 대한 평균, 개수, 합계 등의 옵션을 선택하여 다양한 계산 결과를 표시할 수 있다.
- ②확대/축소 컨트롤을 이용하면 10%~400% 범위 내에서 문서를 쉽게 확대/축소할 수 있다.
- ③자주 사용하는 도구들을 모아서 간단히 추가하거나 제거할 수 있으며, 리본 메뉴 아래에 표시할 수도 있다.
- ④기본적으로 상태 표시줄 왼쪽에는 매크로 기록 아이콘 (
 )이 있으며, 매크로 기록 중에는 기록 중지 아이콘 (
)이 있으며, 매크로 기록 중에는 기록 중지 아이콘 ( )으로 변경된다.
)으로 변경된다.
해설
문제 29
해설
문제 30
해설
문제 31
해설
문제 32
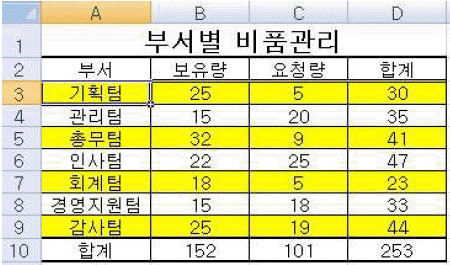
해설
문제 33
해설
문제 34
해설
문제 35
해설
문제 36
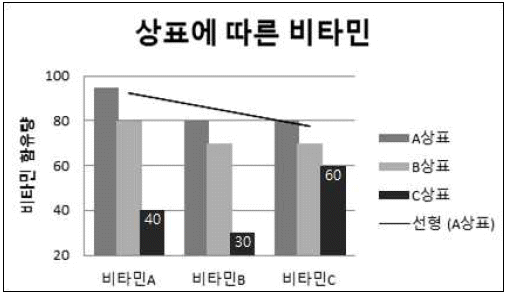
해설
문제 37
해설
문제 38
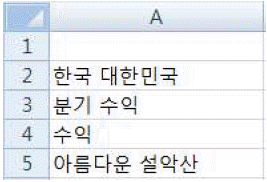
해설
문제 39
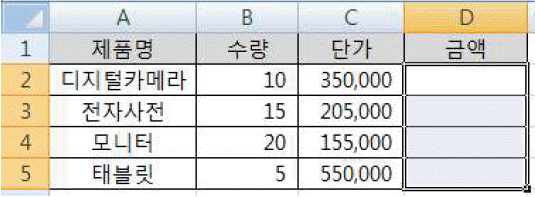
해설
문제 40
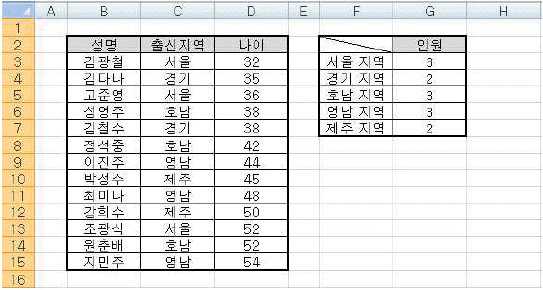
해설
문제 41
해설
문제 42
해설
문제 43
해설
문제 44
해설
문제 45
해설
문제 46

해설
문제 47
해설
문제 48
해설
문제 49
해설
문제 50
해설
문제 51
해설
문제 52
해설
문제 53
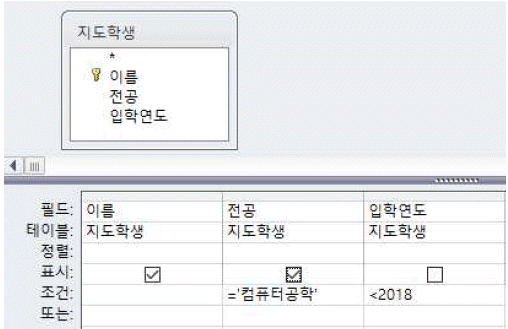
해설
문제 54
해설
문제 55
해설
문제 56
해설
문제 57

해설
문제 58
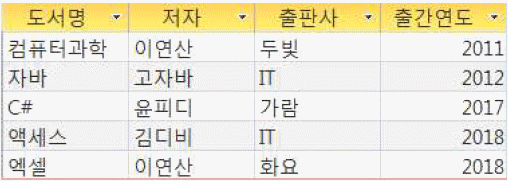
해설
문제 59
해설
문제 60
해설
2018년 컴퓨터활용능력1급 2회차 회차 학습 안내
2018년 컴퓨터활용능력1급 2회차 기출문제 60문항을 회차 단위로 모아 둔 페이지입니다. 화면에서 바로 훑어본 뒤 정답만 포함하거나 해설까지 포함한 시험지로 프린트해 종이 풀이에 쓸 수 있습니다.
회차 전체 풀이
문제 번호를 따로 이동하지 않고 60문항을 한 흐름으로 확인할 수 있어 실제 시험지처럼 이어서 풀기 좋습니다.
정답과 해설 선택
처음 풀 때는 정답을 가리고, 복습할 때는 정답 또는 해설을 포함해 같은 회차를 다시 볼 수 있습니다.
종이 시험지 출력
프린트 옵션을 맞춘 뒤 출력하면 표시해 둔 정답과 해설 포함 상태가 그대로 반영됩니다.
자주 묻는 질문
2018년 컴퓨터활용능력1급 2회차 기출문제는 몇 문항인가요?
2018년 컴퓨터활용능력1급 2회차는 총 60문항으로 구성되어 있습니다. 한 회차 전체를 이어서 보고, 필요한 경우 종이 시험지처럼 출력해 풀 수 있습니다.
정답과 해설을 포함해서 프린트할 수 있나요?
네. 시험 문제 위의 프린트 옵션에서 정답 포함 또는 해설 포함을 선택한 뒤 출력할 수 있습니다. 해설 포함을 켜면 정답도 함께 포함됩니다.
로그인 없이 회차 문제를 볼 수 있나요?
공개된 시험 회차의 문제와 해설은 로그인 없이 확인할 수 있습니다. 학습 진행률, 오답 기록, 북마크처럼 개인별로 이어지는 기능은 로그인이 필요할 수 있습니다.
컴퓨터활용능력1급 기출문제는 어떻게 복습하는 게 좋나요?
처음에는 정답을 가리고 한 회차를 풀어 본 뒤, 틀린 문제만 해설 포함 상태로 다시 확인하는 흐름이 좋습니다. 시험 직전에는 같은 회차를 프린트해 시간 배분과 실수 패턴을 함께 점검해보세요.